데이터베이스 --> 사용하는 이유? 데이터를 잘 찾고 가져다 쓰기 위해
1. 종류
(1) SQL(RDBMS) : 엑셀과 유사(행과 열 미리 정해야함) ex) MS-SQL, My-SQL 등
--> 수정 어려움, 졍형화에 최적화, 데이터 일관적, 분석 빠름
(2) NoSQL (not only SQL) : 한줄 한줄 딕셔너리 형태 ex) MongoDB
--> 자유로움, 유연함, 일관성 부족, 초기스타트업에 유리
※ DB 설치 확인 : 크롬 창에 localhos:27017 검색
ㄴ> It looks like you are trying to access ~~로 뜨면 OK!
※ 서버 = 컴퓨터의 역할
라이브러리 pymongo
--> python에서 쉽게 Mongodb를 사용할 수 있는 라이브러리임
--> 설치 : File > Settings > Python Interpreter > + > pymongo 검색
--> 기본 세팅
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# 코딩 시작
중요 4 POINT
1. insert(삽입)
from pymongo import MongoClient ---------> pymongo를 쓰겠습니다
client = MongoClient('localhost', 27017) ---> 내 컴퓨터에서 지금 돌아가고 있는 mongoDB에 접속할 겁니다
db = client.dbsparta ---> dbsparta 라고 하는 DB 이름으로 접속할 겁니다
doc = {'name':'bobby','age':21} ---> 딕셔너리
db.users.insert_one(doc) ---> db 안에 users라는 컬렉션에 딕셔너리 넣어라
※ 참고사항
▷ MongoDB : 컬렉션(collection)이 존재(비슷한 애들끼리 묶은거)
▷ 파이참에 입력 후 RUN > 로보3T에 가서 users 더블클릭 > 메모장 모양 클릭
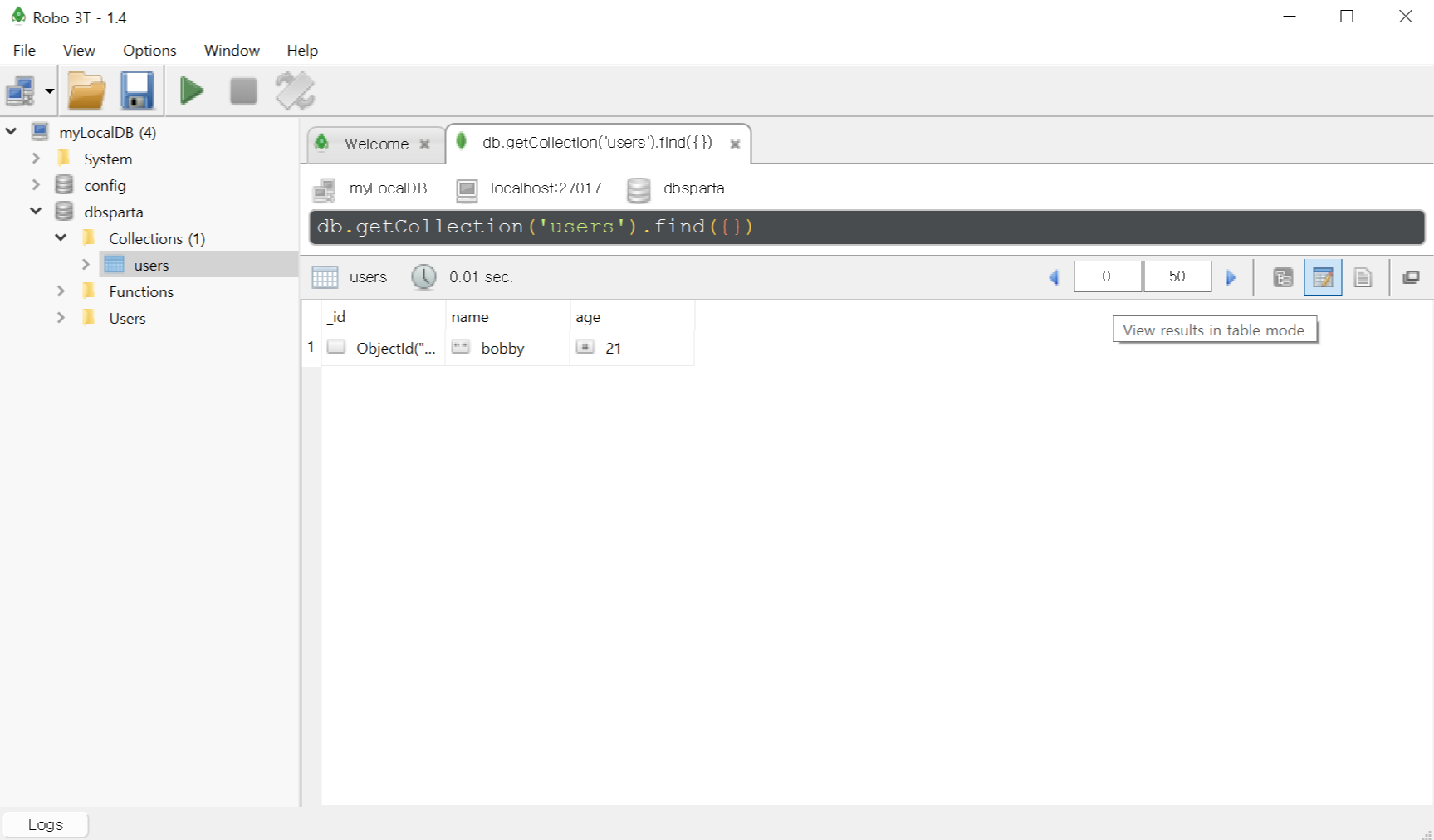
2. find(찾기)
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
same_ages = list(db.users.find({'age':21},{'_id':False}))
print(same_ages)
-----RUN----> [{'name': 'bobby', 'age': 21}, {'name': 'jane', 'age': 21}]
ㄴ> 리스트 안에 딕셔너리
※ 코드 설명
▷ find( { 'age' : 21 }, : 조건 ---> 조건 없을 때는 빈 중괄호로 { }
▷ { '_id' : False } ) : 로보에 임의로 주어지는 id는 가지고 오지마라
1) find : 리스트 형태로 여러개 가져오는 경우
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
same_ages = list(db.users.find({'age':21},{'_id':False}))
for person in same_ages:
print(person)
-------RUN-----> {'name': 'bobby', 'age': 21}
{'name': 'jane', 'age': 21}ㄴ> same_ages는 리스트 안에 있는 딕셔너리이므로 하나씩 출력
2) find_one : 하나만 가져오는 경우
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
user = db.users.find_one({'name':'bobby'}) ---> 이름 bobby 만 가져와라
print(user)
-------RUN-----> {'_id': ObjectId('62b5cf916f1af8ac833199fc'), 'name': 'bobby', 'age': 21}ㄴ> bobby가 여러개 있어도 젤 위에꺼 하나만 가져옴!
ㄴ> id는 필요없으면 {'_id' : False} 추가
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
user = db.users.find_one({'name':'bobby'},{'_id':False})
print(user['age']) -------RUN------> 21
3. update(업데이트, 수정)
1) update_one
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
※ 코드 설명
▷ { 'name' : 'bobby' } : 이름이 bobby인 것을 찾아서
▷ { '$set' : { 'age' : 19 } } : 나이를 19로 바꿔라
▷ 컬렉션 이름 확인할 것!!!!!!!!
2) update_many --> 너무 위험해서 잘 사용 X
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
db.users.update_many({'name':'bobby'},{'$set':{'age':19}})ㄴ> name이 bobby인 사람을 모두 찾아서 나이 19로 바꿔라
4. delete(삭제) --> 잘 사용 X
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
db.users.delete_one({'name':'bobby'})
웹스크래핑 결과 저장하기
1) print --> 파이썬 RUN 화면에서 확인 가능
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr') --> 공통부분 명찰 줌
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
print(rank, title, star)
2) DB 저장 --> RUN > collections 우클릭 > refresh > movies 파일 생성 > 내용 확인
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
doc = {
'rank' : rank, --------> 'rank'라는 이름으로 rank 넣기
'title' : title, --------> 'title'라는 이름으로 title 넣기
'star' : star --------> 'star'라는 이름으로 star 넣기
}
db.movies.insert_one(doc)※ 코드 설명
▷ DB 저장 위해선 from pymongo import MongoClient 기본 세팅 필수임!!!!
client = MongoClient('localhost', 27017)
db = client.dbsparta
▷ insert 기본 세팅 : doc = {'name':'bobby', 'age':21} ----> document 딕셔너리 만들기
db.users.insert_one(doc)
▷ collection name 설정 : users 가 아닌 movies(적당한 이름)로 수정할 것★
퀴즈
1) 영화제목 '매트릭스'의 평점 가져오기
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
movie = db.movies.find_one({'title':'매트릭스'})
print(movie['star']) ------RUN-----> 9.39ㄴ> 지칭명사 = db.저장파일이름.find_one( { 찾고자하는 조건} )
2) '매트릭스'의 평점과 같은 평점의 영화 제목들을 가져오기
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
movie = db.movies.find_one({'title':'매트릭스'})
target_star = movie['star']
same_stars = list(db.movies.find({'star':target_star}))
print(same_stars)ㄴ> print 를 하면 가로로 길게 나와서 보기 어려움 (이런 경우엔 사용 X)
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
movie = db.movies.find_one({'title':'매트릭스'})
target_star = movie['star']
same_stars = list(db.movies.find({'star':target_star}))
for same in same_stars:
print(same['title'])ㄴ> for in 구문 사용하면 딕셔너리가 한줄씩 예쁘게 나옴
3) 매트릭스 영화의 평점을 0으로 만들기
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
db.movies.update_one({'title':'매트릭스'},{'$set':{'star':0}})ㄴ> print X , 작성 후 RUN > robo에서 새로고침하면 OK
※ 참고사항
▷ Robo) 평점 보면 " " 9.39 (문자열) # 9.39(숫자) 형식임
3주차 과제 : 지니뮤직의 1~50위 곡 스크래핑하기
https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1
지니차트>일간 - 지니
AI기반 감성 음악 추천
www.genie.co.kr
1) 기본 세팅하기
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
2) 제목 나오게 하기
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis')
print(title.text)
ㄴ> 각 노래 제목 사이사이에 공백이 엄청 크게 있음
구글링 : 파이썬 print 공백 제거
해결 : title = tr.select_one('td.info > a.title.ellipsis').text.strip()
※ 파이썬 공백 제거
▷ strip() : 양측 공백 제거,
▷ lstrip() : 좌측 공백 제거(left + strip)
▷ rstrip() : 우측 공백 제거(right + strip)
3) 가수 가져오기
for tr in trs:
name = tr.select_one('td.info > a.artist.ellipsis').text
print(name)
4) 순위 가져오기
for tr in trs:
rank = tr.select_one('td.number').text
print(rank)ㄴ> 순위 + 상승,하강 정도 까지 나옴 & 공백
구글링 : 파이썬 span 제거 > 글자 제거 > 문자열 자르기
해결 : rank = tr.select_one('td.number').text[0:2].strip()
※ 파이썬 문자열 제거
▷ strip : 불필요한 문자열 제거(해당 문자열 괄호에 적기)
▷ replace : 지정 문자열을 치환하여 제거
▷ translate : 여러개의 문자열 한번에 치환 또는 제거
▷ re.sub : 복잡한 패턴의 문자열 치환하여 삭제(import re 해야함)
※ 파이썬 문자열 슬라이싱
▷ slice : 문자열 length의 범위를 지정하여 필요한 부분만 사용
ex) string = "hello world" --> length(11)
string[ 0 : 5 ] --> ' hello ' (시작 : 끝 위치)
5) 완성본
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text[0:2].strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
name = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, name)1 아로하 조정석
2 시작 가호 (Gaho)
3 처음처럼 엠씨더맥스 (M.C the MAX)
4 이제 나만 믿어요 임영웅
5 아무노래 지코 (ZICO)
6 흔들리는 꽃들 속에서 네 샴푸향이 느껴진거야 장범준
7 뭔가 잘못됐어 권진아
8 WANNABE ITZY (있지)
9 돌덩이 하현우 (국카스텐)
10 어떻게 지내 (Prod. by VAN.C) 오반
11 METEOR 창모 (CHANGMO)
12 화려하지 않은 고백 규현 (KYUHYUN)
13 그때 그 아인 김필
14 Blueming 아이유 (IU)
15 문득 노을
16 마음을 드려요 아이유 (IU)
17 ON 방탄소년단
18 늦은 밤 너의 집 앞 골목길에서 노을
19 좋은 사람 있으면 소개시켜줘 조이 (JOY)
20 뜸 WINNER
21 Psycho Red Velvet (레드벨벳)
22 FIESTA IZ*ONE (아이즈원)
23 반만 진민호
24 2002 Anne-Marie
25 HIP 마마무(Mamamoo)
26 오늘도 빛나는 너에게 (To You My Light) (Feat.이라온) 마크툽 (Maktub)
27 어떻게 이별까지 사랑하겠어, 널 사랑하는 거지 AKMU (악뮤)
28 작은 것들을 위한 시 (Boy With Luv) (Feat. Halsey) 방탄소년단
29 Memories Maroon 5
30 Don't Start Now Dua Lipa
31 안녕 폴킴
32 다시 난, 여기 백예린 (Yerin Baek)
33 모든 날, 모든 순간 (Every day, Every Moment) 폴킴
34 Love poem 아이유 (IU)
35 바빠서 (Feat. 헤이즈) 개코
36 꽃 (flower) (Feat. 박재범 & 우원재 & 기리보이) 코드 쿤스트 (CODE KUNST)
37 Square (2017) 백예린 (Yerin Baek)
38 노래방에서 장범준
39 bad guy Billie Eilish
40 조금 취했어 (Prod. by 2soo) 임재현
41 잘 지내고 있는지 궁금해 V.O.S
42 시든 꽃에 물을 주듯 HYNN (박혜원)
43 새로고침 (Feat. 강민경 of 다비치) 박경
44 사랑이란 멜로는 없어 전상근
45 벚꽃 엔딩 버스커 버스커 (Busker Busker)
46 우리 왜 헤어져야 해 신예영
47 사랑의 인사 씨야 (SeeYa)
48 아무렇지 않게, 안녕 HYNN (박혜원)
49 Paris In The Rain Lauv
50 주저하는 연인들을 위해 잔나비
3주차 완주!!!!!!!!!!
데이터베이스 생각보다 진짜 재밌다!! 4주차 말고 3주차만 계속 하고싶을 정도로....
B.U.T, 쉬지않고 열심히 달린다!!!
노트북 하나로 해서 왔다갔다가 조금 힘들지만 확실히 노선이 정해지면 듀얼모니터부터 산다ㅠㅠ

'Python > Web_log' 카테고리의 다른 글
| 22.06.28(화) (0) | 2022.06.28 |
|---|---|
| 22.06.27(월) (0) | 2022.06.27 |
| 22.06.23(목) (0) | 2022.06.23 |
| 22.06.04 (0) | 2022.06.23 |
| 22.06.22(수) (0) | 2022.06.23 |
